Najeli jsme na mělčinu aneb proč mělo Freelo včera navečer 27 minut dlouhý výpadek


Dostupnost Freela bereme velmi vážně. Máme celou řadu mechanizmů, které nám pomáhají s Freelem plout dlouhé měsíce i roky bez výpadku. Včera v podvečer se bohužel stalo, že jsme na 27 minut najeli na mělčinu. V článku se dozvíte příčinu, ponaučení, opatření a taky pár konkrétních způsobů, nástrojů a aplikací, díky kterým má Freelo vysokou dostupnost.
Vysvětlení pro každého
- V pondělí 2.11.2020 v 16:14 jsme obdrželi informaci o tom, že se neodbavuje fronta zpráv.
- V zápětí jsme začali řešit, čím to je a jak to opravit.
- V 18:05 jsme najeli na mělčinu – Freelo bylo nedostupné.
- Zkoušení restartu různých služeb, které by s problémem mohly souviset. Bohužel bez uspokojivého výsledku.
- Zkoumání vedlo k Zaseknuté databázi.
- Odhalili jsme příčinu, zaseklý dotaz jsme odjistili a po 27 minut dlouhém výpadku bylo Freelo zpět na širém moři.
- Udělali jsme opatření, aby se podobný problém už neopakoval.
Vysvětlení pro technické nadšence
Včera v odpoledních hodinách do slack kanálu #servery přišlo upozornění na plnící se frontu zpráv. To byl pro nás blikající maják značící útesy někde poblíž. Frontu zpráv používáme pro optimalizaci rychlosti. Když třeba kliknete na tlačítko dokončit úkol, tak uložíme zprávu do fronty dokončený úkol a na obrazovce přeškrtneme daný úkol. Všechny následné zdlouhavé činnosti jako červenání zvonečků s notifikacemi celé posádce na projektu, posílání emailů, webhooky a další věci se dějí až když jiná část aplikace vyzvedne zprávu o hotovém úkolu z této fronty.
Pro správný chod Freela je potřeba, aby tato fronta byla ideálně prázdná a zprávy se odbavovaly ideálně hned.
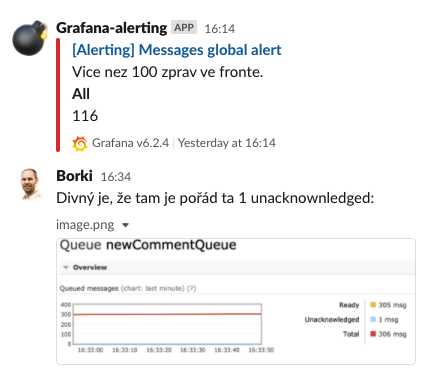
Hledání problému
Ptali jsme se sami sebe: „Proč skripty, které vybírají zprávy z fronty, běží, ale fronta stále roste?“ Začali jsme prohlížením logů:
- supervisor
- rabbitmq
- syslog
- logy přímo z aplikace
- nginx
- php
- a další
Vypnout a zapnout
Nic kloudného jsme nemohli najít, takže přišla na řadu pokročilá IT věda. Vypnout. Zapnout. Restartovat.
- Jako první supervisor – ten se právě stará o skripty, které vybírají zprávy. Když neběží, tak je sám spustí atd. Na chvilku to pomohlo, ale po chvilce fronta zase začala narůstat.
- Pak jsme začali zkoumat spouštění těchto skriptů přímo z příkazové řádky. Výsledek byl dost podobný.
- Restart rabbitmq (fronta zpráv). Bez změny.
Jsme na mělčině
Skripty i většina aplikace jsou psané v jazyce PHP, takže po prozkoumání logů PHP a Nginx jsme šli restartovat webserver. Věděli jsme, že tady už uděláme mikro výpadek. Jenže! V rámci PHP tam visel nedokončený proces, který nešel ukončit, byl ve stavu „D“ – waiting for resources.
Nakonec se nám ho podařilo ukončit a měli jsme trochu vodítko, že problém bude jinde. Po úspěšném restartu webserveru vyplulo Freelo zase z mělčiny, jenom se plnila opět fronta.
Začali jsme tedy pátrat po všech externích službách a serverech. Restartovali jsme třeba SMTP servery, které po dokončení úkolu posílají e-mailové notifikace. Nakonec jsme se zastavili nad databázovým serverem PostgreSQL. Ten v logu nic podivného neměl ani nebyl vytížený. Při nahlédnutí pod pokličku běžících procesů jsme našli dotaz, který byl ve stavu idle in transaction. Kvůli tomu tam byl zámek a další stovka akcí čekala. Po ukončení tohoto SQL dotazu se vše okamžitě rozběhlo.
Více o této problematice zaseklého dotazu je v tomto článku.
Změny a ponaučení
Aby se to neopakovalo, tak jsme zařídili ihned 2 věci:
- Kontrolu procesů, které jsou ve stavu
idle in transaction. Opět s napojením na náš Slack. - A zároveň i automatické zabíjení takových procesů po stanovené době.
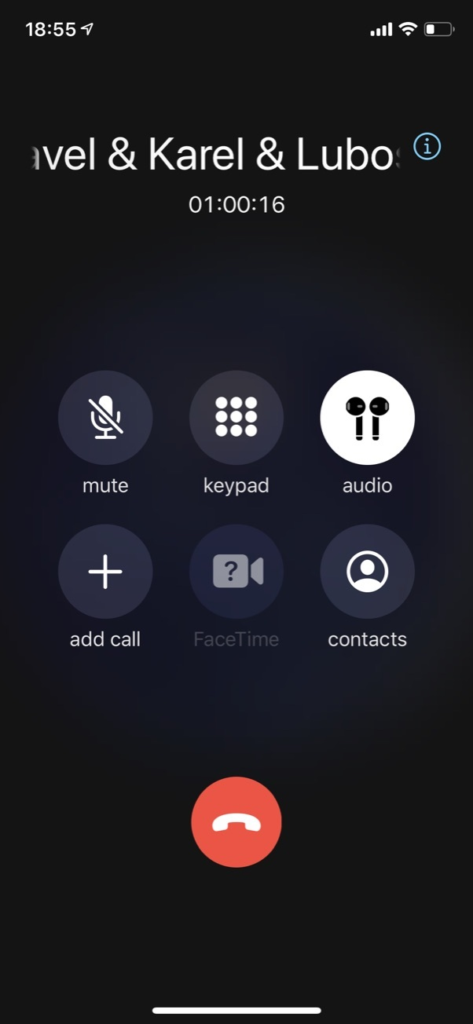
Téměř po celou dobu jsme byli na telefonu s dvěma serverovými specialisty a průběžně jsme si sdělovali, co komu přijde divné, co kdo zrovna zkoumá. Tenhle simultánní brainstorming a skládání hypotéz řešení hodně urychlilo. Budeme podobně postupovat i při dalším výpadku.
Jak hlídáme dostupnost?
Dostupnost je pro aplikaci, jako je Freelo, velmi důležitá a nic nenecháváme náhodě. Základní metriky a warningy řešíme pomocí Slacku, Grafany a Prometheusu. Obvykle nejde o nic zásadního, spíše nás služby upozorní včas na blížící se problém.
Akutní problém a nedostupnost hlídáme pomocí monitoringu serverů — Hlidam.to. Ta drží stráž nad aplikací, databází, weby, blogem, expirací certifikátů a hlídá taky i to jestli jsou naopak některé věci nedostupné — tím se myslí třeba naše interní systémy jako fakturační systém. Ten musí být dostupný pouze z naší VPN. Takže vlastně proaktivně hlídáme jejich nedostupnost.
Když je problém, tak se nám odesílají e-maily a SMS na několik telefonních čísel.

Když do podpalubí hodně teče, tak Hlidam.to zavolá dvěma lidem (Praha a Pardubice). Ti mají doma permanentně na nabíječce elegantní aligátory s velmi hlasitým a otravným zvoněním, které v noci opravdu slyšet nechcete.
Monitoring z celého světa
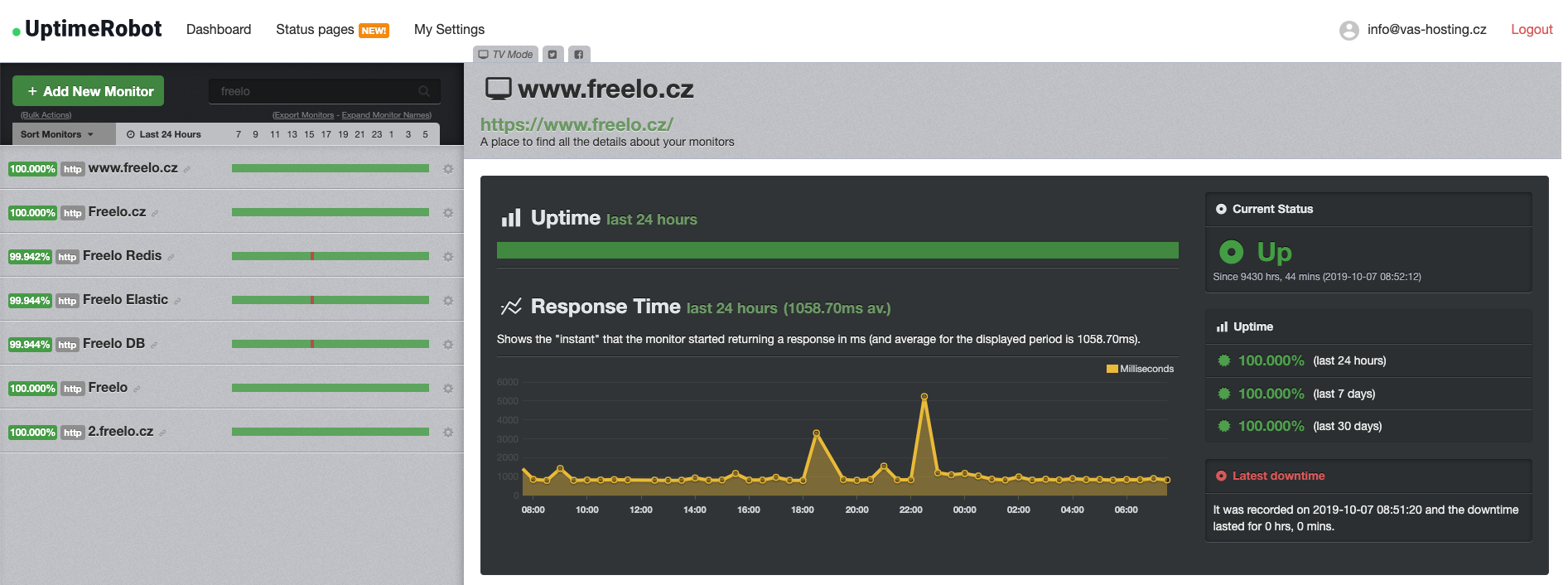
Pro stoprocentní jistotu celosvětové dostupnosti používáme ještě službu Uptimerobot, kde máme základní kontrolu dostupnosti aplikace.
Výpadek nás moc mrzí a omlouváme se za něj všem námořníkům a kapitánům. Letos byl první a doufáme, že i poslední. Každý den leštíme strojovnu, aby plavba vašich firem a týmů ve Freelu byla klidná a bez zbytečných uvíznutí na mělčině.
Děkujeme, že plujete s námi.